
High Performance C++ Designs with AMD Vitis™ HLS
By AMD, Advanced Micro Devices
Introduction
AMD offers comprehensive, multi-node FPGA and adap-
tive SoC portfolios to address requirements across a wide set of applications—whether you are designing a state-of-the-art, high-performance networking application requiring the high- est capacity, bandwidth, and performance, or looking for a low- cost, small footprint device.
For the levels of integration these circuits offer, the impor- tance of high-level synthesis (HLS) is crucial. And it is not just productivity gains; it is also the expressiveness of C++ to effi- ciently and concisely code algorithms. C++ offers several ad- vantages including advanced data structures, types, and math functions that are not available out-of-the-box in classic design flows based on Verilog or VHDL. Also, importantly, the func- tionalverificationspeedwithC++isamammothadvantage over RTL simulators. Another core C++ advantage is that after synthesis, the verification of the generated RTL with the same testbench is available.
High-level synthesis for C++ is bundled into the new AMD Vitis™ Unified IDE. This AMD Vitis HLS tool is ideal for video and DSP algorithms. It maps them onto the logic fabric, while the AI Engines, the vector processor in AMD Versal™ devices, come with their own compiler, which is not covered in this ar- ticle. For more information about the Versal AI Engine vector processors, visit us on
The new AMD Vitis IDE offers a bottom-up approach that allows the creation of components for either the fabric (often referred to as the programmable logic) or onto the AI Engines.
Floating-Point Fast Fourier Transform in C++
To illustrate the capabilities of AMD Vitis™ HLS, let us look at a fast Fourier transform (FFT) written in just 80 lines of C++. The code example is open-source, available on GitHub-Xilinx/ pp4fpgas.
We should note that with Vitis HLS, you also have the op- tion to instantiate an AMD LogiCORE™ FFT IP, available in the AMD Vivado™ IP Catalog, but here we use a generic C++ FFT. This has several advantages over writing RTL or using a pre-designed IP: the code is compact, portable, and easily customizable. Compactness relative to RTL stems from the untimed nature of C++, which leaves it to the compiler to in- sert registers in the generated RTL to meet FMAX goals. In addition, Vitis HLS can optionally include AXI adapters to the design ports.
The data type is “float” (single-precision floating-point), which is natively supported in Versal DSP Engines. Designing an FFT with floating-point compared to fixed- point has the advantage of not having to manage bit growth.
Notice the pragmas in the code; they direct the compiler optimizations and help ensure, in this case, that all the tasks in the code region operate in paral-lel. These tasks correspond to the FFT stages delin- eated (unrolled) in the stage loop. This nudges the compiler to map these iterations as a succession of distinct fft_stage calls, which allows for parallel exe- cution of these different stages rather than reusing a single block of logic (and become a bottleneck).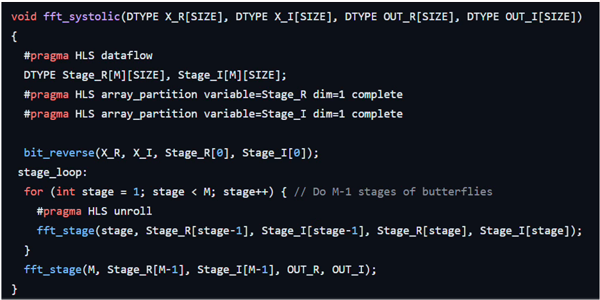
Analyzing the Results and Measuring Performance
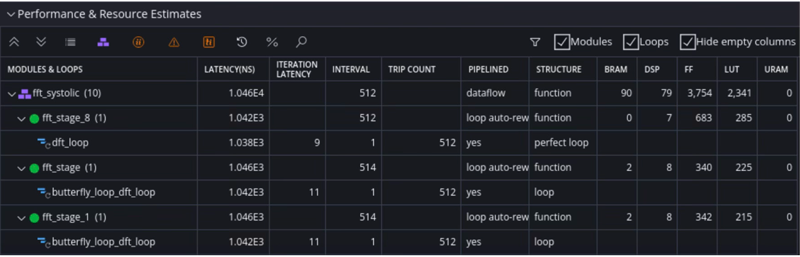
First, the focus should be on the main synthesis report as it can tell us how well these loops are performing. The “interval” indicates the number of clock cycles before another iteration can be launched independently of the iteration latency, which is another column of the report. We can also see that the data- flow architecture is implemented in the “pipelined” column.
Later, the report also confirms the type of interfaces used to connect our generated RTL to other elements of the design
outside of this Vitis HLS block. The performance of the FFT can be measured by its ability to process incoming “frames” of data continuously; this is where the timeline trace is useful. With several invocations of the FFT, the trace shows idle time (if any) between the invocations.
The following graph is a timeline trace view in the Vitis tool. The view is available after simulation of the RTL is generated by C synthesis; the test vectors are the same as the ones in the original C++ testbench.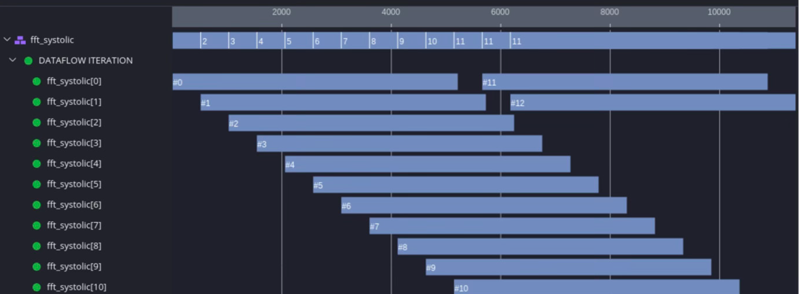
A 500 MHz target is attainable in Versal devices mostly be- cause the Versal DSP Engine has native floating-point support for multipliers and adders.
This FFT C++ code can be reused as is for other AMD FPGA architectures. To see the effect of actual place and route results, implement the design in the Vivado Design Suite.
Some quantitative results for this 1,024-point FFT:
Conclusion
C++ algorithms yield high-performance results when com-
piled with AMD Vitis HLS tool. The source code typically re- quires adaptation to create an efficient description mappable onto hardware. The Vitis IDE helps synthesize and validate performance goals through text reports and graphical tools.
Functional verification is fast depending on the amount of data sent by the testbench.
The AMD Vitis software platform helps develop designs that include FPGA fabric, Arm® processor subsystems, and AI En- gines. The higher level of abstraction for design development helps to reduce design times.