
Performance from Nvidia continues to change the world.
TensorRT 7 – Accelerate End-to-end Conversational AI with New Compiler
NVIDIA’s AI platform is the first to train one of the most advanced AI language models — BERT (Bidirectional Encoder Representations from Transformers) — in less than an hour and complete AI inference in just over 2 milliseconds. This groundbreaking level of performance makes it possible for developers to use state-of-the-art language understanding for large-scale applications they can make available to hundreds of millions of consumers worldwide.
Early adopters of NVIDIA’s performance advances include Microsoft and some of the world’s most innovative startups, which are harnessing NVIDIA’s platform to develop highly intuitive, immediately responsive language-based services for their customers.
Limited conversational AI services have existed for several years. But until this point, it has been extremely difficult for chatbots, intelligent personal assistants and search engines to operate with human-level comprehension due to the inability to deploy extremely large AI models in real time. NVIDIA has addressed this problem by adding key optimizations to its AI platform — achieving speed records in AI training and inference and building the largest language model of its kind to date.
“Large language models are revolutionizing AI for natural language,” said Bryan Catanzaro, vice president of Applied Deep Learning Research at NVIDIA. “They are helping us solve exceptionally difficult language problems, bringing us closer to the goal of truly conversational AI. NVIDIA’s groundbreaking work accelerating these models allows organizations to create new, state-of-the-art services that can assist and delight their customers in ways never before imagined.”
How Bert Works
BERT uses Transformer that learns the contextual relationship between words in a text. Transformers include two separate mechanisms – an encoder that reads the text input and a decoder that produces a prediction for the task. In directional modes, which read text left-to-right, the Transformer encoders read the entire sequence of words at once. By reading the entire sequence at once it allows the model to learn the context of the words based on all of its surrounding (left and right of the word).
Using two training strategies, BERT over comes the directional approach that limits context learning and creates a richer predictive model.
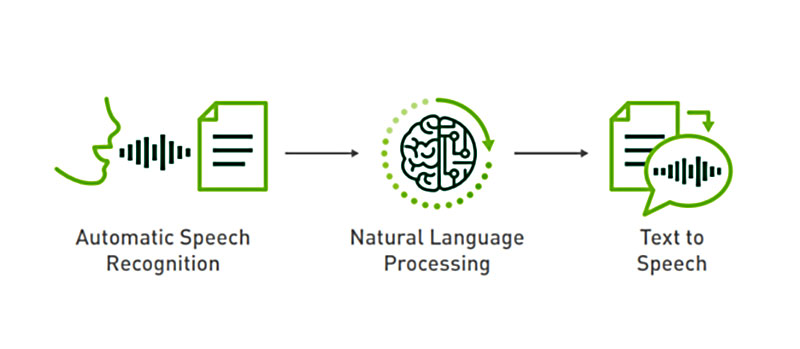
TensorRT-7
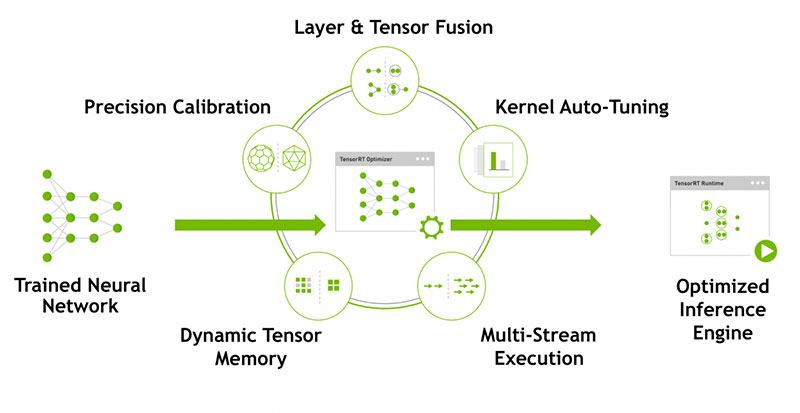
TensorRT™ is an SDK for high-performance deep learning inference. It includes a deep learning inference optimizer and runtime that delivers low latency and high-throughput for deep learning inference applications. TensorRT-based applications perform up to 40x faster than CPU-only platforms during inference. With TensorRT, you can optimize neural network models trained in all major frameworks, calibrate for lower precision with high accuracy, and finally deploy to hyperscale data centers, embedded, or automotive product platforms.
TensorRT is built on CUDA, NVIDIA’s parallel programming model, and enables you to optimize inference for all deep learning frameworks leveraging libraries, development tools and technologies in CUDA-X for artificial intelligence, autonomous machines, high-performance computing, and graphics.
TensorRT provides INT8 and FP16 optimizations for production deployments of deep learning inference applications such as video streaming, speech recognition, recommendation and natural language processing. Reduced precision inference significantly reduces application latency, which is a requirement for many real-time services, auto and embedded applications
You can import trained models from every deep learning framework into TensorRT. After applying optimizations, TensorRT selects platform specific kernels to maximize performance on Tesla GPUs in the data center, Jetson embedded platforms, and NVIDIA DRIVE autonomous driving platforms.
TensorFlow 2.0 with Tighter TensorRT Integration
To help developers build scalable ML-powered applications, Google released TensorFlow 2.0, one of the core open source libraries for training deep learning models. In this release, developers will see up to 3x faster training performance using mixed precision on NVIDIA Volta and Turing GPUs.
TensorFlow 2.0 features tighter integration with TensorRT, NVIDIA’s high-performance deep learning inference optimizer, commonly used in ResNet-50 and BERT-based applications. With TensorRT and TensorFlow 2.0, developers can achieve up to a 7x speedup on inference.
This update also includes an improved API, making TensorFlow easier to use, along with higher performance during inference on NVIDIA T4 GPUs on Google Cloud.
For use in multiple GPUs, developers can use the Distribution Strategy API to distribute training with minimal code changes with Keras’ Model.fit as well as custom training loops.
Using MATLAB and TensorRT on NVIDIA GPUs
MathWorks released MATLAB R2018b which integrates with NVIDIA TensorRT through GPU Coder. With this integration, scientists and engineers can achieve faster inference performance on GPUs from within MATLAB.
The high-level language and interactive environment MATLAB provides enables developers to easily create numerical computations and algorithms with various visualization and programming tools.
A new technical blog by Bill Chou, product manager for code generation products including MATLAB Coder and GPU Coder at MatWorks, describes how you can use MATLAB’s new capabilities to compile MATLAB applications into CUDA and run on NVIDIA GPUs with TensorRT. The example workflow includes compiling deep learning networks and any pre- or post processing logic into CUDA, testing the algorithm in MATLAB, and integrating the CUDA code with external applications to run on any modern NVIDIA GPU.
When using TensorRT with GPU Coder for a simple traffic sign detection recognition (TSDR) example written in MATLAB, the team noticed 3x higher inference performance with TensorRT running on Titan V GPUs compared with a CPU-only platform.